How We Built Repliear: Compound Filters
May 20, 2022
Repliear is a demo app we built to show off what’s possible with Replicache. It’s a re-implementation of a subset of the Linear issue tracker.
Just like the real Linear, when the user takes any action in Repliear, the UI responds instantly, with no server round-trip, and changes from other users appear automatically in realtime. This works even with significant data — the sample dataset is all eleven thousand issues from the React project and weighs in at about 50 MB.
Watch a video demo below, or try it out yourself.
Most teams report that building the realtime sync infrastructure required for these kind of applications takes several person-years to build from scratch. Repliear took two engineers on our team 6 weeks and the resulting app is only about 5k lines of code.
In this post, we discuss our implementation of one of Linear's most distinctive features: client-side compound filters. Implementing this on top of Replicache was an interesting challenge. The technique we describe could be useful to other large or performance sensitive Replicache applications.
Compound Filters
Linear allows you to construct arbitrary compound filters over the entire dataset that respond instantly:
What makes this feature interesting for Replicache is that we wanted to demonstrate it with relatively large workloads. The React issue dataset we use in our sample contains 11k issues and ~50MB of structured data. The metadata (not counting descriptions and comments) is about 2.5MB.
UI is typically built in Replicache using subscriptions. And they work great as long as they read a reasonable amount of data out of Replicache per run, say < 1MB.
But a filter that has a small number of results might easily have to scan the entire dataset to get those results. Replicache scans at about 500MB/s on mid-tier hardware, so to scan all the metadata would be 5ms. And that’s just to iterate the data, and doesn’t include any of the filtering, sorting, or rendering. That’s an uncomfortable chunk of our 16ms frame budget. And it would happen on any change to the data and during scroll to refill the virtual scroll window.
Replicache does have first-class indexes which provide fast filters on a single key. But using indexes for compound multi-key queries is a much harder problem. Even modern databases with sophisticated query planners struggle to find the best index(es) to use for a query.
A Simpler Solution
Both subscriptions and indexes felt like we were trying to shoehorn Replicache features into a problem they weren’t right for. So we stepped back and asked ourselves “How would we build this if we weren’t the Replicache team and we just chose the best engineering solution?”
With that framing, we quickly settled on maintaining an in-memory computed “view” of issue metadata (i.e., the issue data minus its detailed description and comments) that matched the user’s current filter/sort selections. When data in Replicache changed, we’d only have to find the right place to surgically modify the view, not recompute the entire thing. We could build the view using the same modification logic, so the whole system would remain DRY.
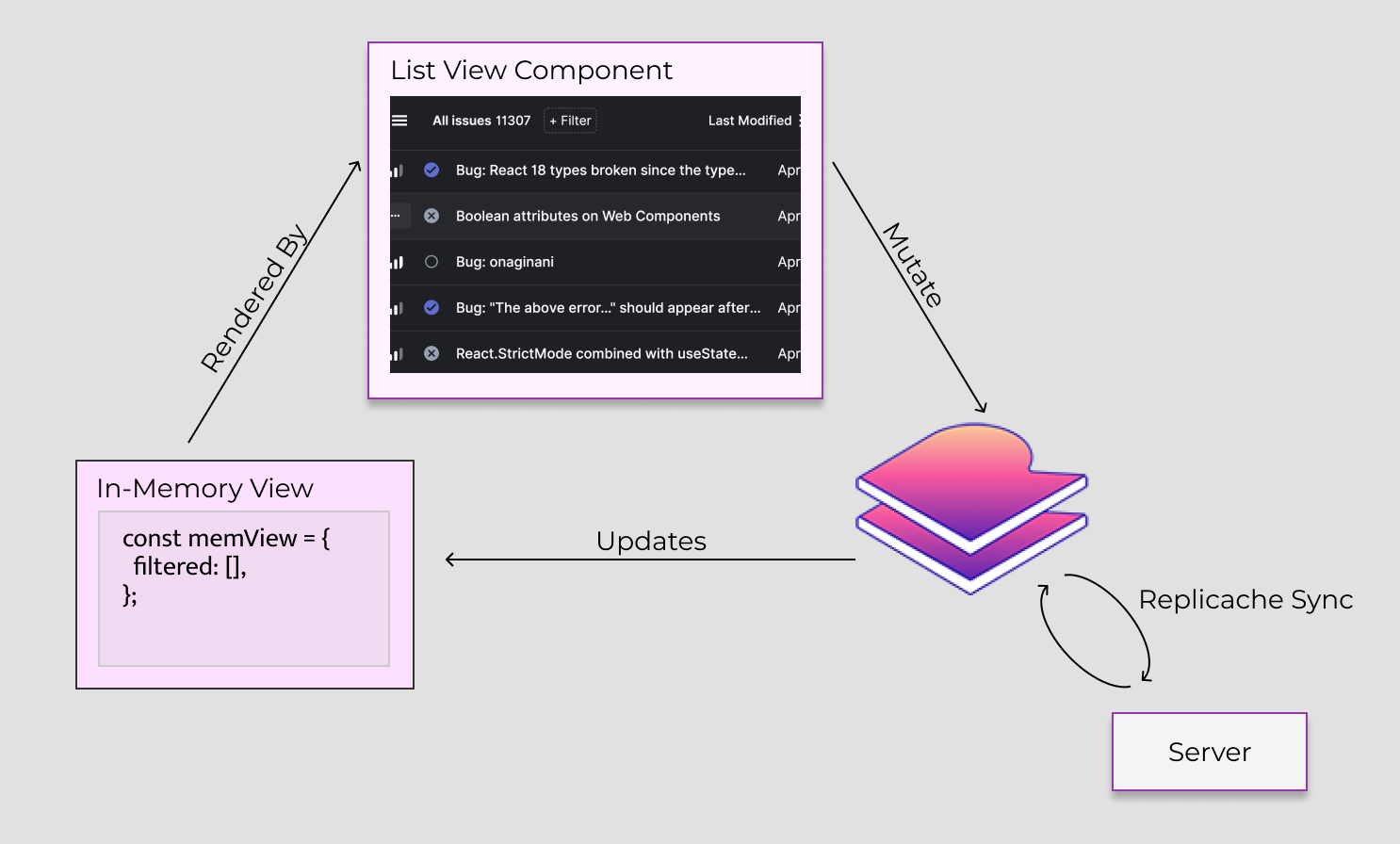
With this design, we might drop a frame worst case when changing the filter picker as we rebuilt the view. But otherwise, our UI updates would be guaranteed snappy, since they only have to make tiny changes to a view which is already built. And the performance of view updates would scale logarithmically with the dataset size (because it’s basically just map edits).
Note: There's a complexity tradeoff here: The view update code is more complex than simply rendering the results of a subscription. We decided the complexity was worth it, and likely what our customers would choose too.
Watching Replicache
In order to implement this, we needed fine-grained delta updates from Replicache to update our view.
Replicache already tracked this information internally, it just wasn’t exposed anywhere. We designed a new method, watch(), for tracking fine-grained changes, and used it to maintain our in-memory view. In essence it works something like:
const memView = {
filtered: [],
};
// every watch event triggers a reducer
rep.experimentalWatch(
(diff) => {
dispatch({
type: "diff",
diff,
});
},
{ prefix: ISSUE_KEY_PREFIX, initialValuesInFirstDiff: true }
);
// example of handling diff operation "change" in a reducer
const newFiltered = [...state.filtered];
for (const diffOp of diff) {
// del and change cases
if (diffOp.oldValue) {
const oldIssue = diffOp.oldValue;
if (state.filter(oldIssue)) {
const index = sortedIndexBy(newFiltered, oldIssue, state.order);
if (newFiltered[index]?.id === oldIssue.id) {
newFiltered.splice(index, 1);
}
}
}
// change and add cases
if (diffOp.newValue) {
const newIssue = diffOp.newValue;
if (state.filter(newIssue)) {
newFiltered.splice(
sortedIndexBy(newFiltered, newIssue, state.order),
0,
newIssue
);
}
}
}
return {
...state,
filtered: newFiltered
};
(See the complete production code)
To mutate the data, we use Replicache mutators as normal. Replicache runs the watch() handler with the diff immediately after mutations. The watch handler updates the in-memory view, and the UI re-renders.
In the background, Replicache syncs with the server. Any changes from the server are applied to the client view, and if there are differences, watch() fires again, which updates the in-memory view and the UI updates again.
Notice how all changes flow unidirectionally through Replicache. This ensures that the UI always shows a consistent view of state, whether it changed because of local changes or server changes.
Conclusion
Repliear demonstrates a real-world app of significant complexity built with Replicache.
An interesting challenge of these apps is to provide the extremely low latency updates and queries needed for interactive applications, even when the data size gets larger.

Repliear's filter picker. Like many things in software, the difficulty of this problem comes in options 0, 1, or n. We implemented two filters, but the technique scales to any number.
Most Replicache customers won’t need anything more than the higher-level subscription API. But as your application does get larger, watch() is a new low-level way to use Replicache can provide much better performance at the cost of some additional complexity.
Ready to start?
You can get started with Replicache in about five minutes (a few more if you need to download Docker 😜).
More questions? Comments? Contact us on Discord, Twitter or by email. We would love to talk.